")
Una de las novedades que ha introducido XE, es la integración dentro de la llamada RTL (Run Time Library) de Delphi, de las Expresiones regulares, aspecto que ya estaba integrado en nuestro IDE, a través de una de las opciones de búsqueda pero que no se había hecho disponible hasta hoy de forma oficial dentro del entorno para nuestro uso en los proyectos.
En la ayuda de Delphi podeis acceder con este link, [ms-help://embarcadero.rs_xe/rad/VCL_and_RTL_Changes_for_XE.html], en donde se recogen los cambios de versión o novedades dentro de la VCL y RTL citados en el parrafo anterior.
Para empezar a trabajar con las Expresiones Regulares basicamente, tendremos que añadir a la clausula uses del módulo del proyecto que va a utilizarlas, la unidad RegularExpressions, que es la unidad que declara e implementa las clases que vamos a necesitar. Si accedeis a la información de la ayuda en linea, vereis que aparecen un conjunto de clases (7):
| TGroup | Un registro que contiene el resultado de una coincidencia con una porción de una expresion regular. |
| TGroupCollection | Colección de instancias de TGroup. |
| TGroupCollectionEnumerator | Contiene funciones y propiedades para recorrer los resultados de la colección de grupos. |
| TMatch | Un registro conteniendo los resultados de una coincidencia con la expresión regular. |
| TMatchCollection | Colección de instancias de TMatch. |
| TMatchCollectionEnumerator | Contiene funciones y propiedades para recorrer los resultados de la colección de coincidencias. |
| TRegEx | Un registro para manejar las expresiones regulares, |
Lo cual, en principio no resulta demasiado claro, al menos si no se puede ver en un ejemplo o se ha trabajado anteriormente con Expresiones Regulares. Afortunadamente existen algunos ejemplos dentro de la ayuda bastante útiles por lo que considero que podemos remitirnos a ellos como guía.
Dentro de la dockwiki de embarcadero podéis acceder al link que contiene ejemplos nuevos propios de Xe http://docwiki.embarcadero.com/CodeExamples/en/Category:XE y ya dentro de esta página, yo eligiría para empezar a entender como se relacionan las distintas clases el vínculo: http://docwiki.embarcadero.com/CodeExamples/en/TMatchCollectionCount_(Delphi)
Pero antes de ver cualquier ejemplo, parece que lo mas apropiado es hacer una pequeña reseña al concepto de Expresiones Regulares, de forma que quien se ha podido acercar por primera vez al tema sepa de que hablamos. Así que, podemos dividir este artículo en dos entradas: ésta para intentar comprender las expresiones regulares y una segunda parte abordando el conjunto de clases de la unidad Regular Expressions.
Para empezar, decir simplemente que las expresiones regulares se remontan a la decada de 1950, en la que Kleene, lógico y matemático estadounidense, daba los primeros pasos al relacionar expresiones regulares y autómatas finitos.
Una expresión regular representa un patrón de cadenas de caracteres y se define por el total del conjunto de cadenas con las que concuerda o coincide. Es decir, a partir de un patrón fijado por nosotros encontramos un numero indeterminado de cadenas que podrían coincidir con el y que confortan lo que podríamos considerar el dominio de aplicación de dicho patrón o lenguaje de la expresión.
Un ejemplo: la expresión regular ‘abc|d’ admitiría las cadenas ‘abc’ ó ‘d’ pero no otras, dentro de ese lenguaje.
En la práctica, si consideraramos dentro de nuestro patrón los caracteres ASCI o cualquier subconjunto del mismo, podríamos denominar a dicho conjunto como su alfabeto. Imaginad uno cualquiera de esos alfabetos (|a|, |b|.. |z|), veremos que existen 3 operaciones básicas que podríamos considerar respecto a la forma en que se interrelacionan: la primera podría ser la la selección de alternativas, ya vista en el ejemplo anterior. El caracter ‘|’ nos ha permitido discriminar dos opciones. Este tipo de caracteres que tienen un significado especial reciben el nombre de Metacaracteres o metasímbolos y no serían legales en el alfabeto, a no ser que exista otro metacaracter que desactive su valor especial. La segunda operación básica sería la Concatenación, que se formaría por yuxtaposición (sin metacaracter). Esta operación nos permitiria enlazar o unir caracteres para formar una expresión. En el ejemplo anterior, ha permitido considerar ‘abc’ como agrupación de varios caracteres del alfabeto. Finalmente, existe la repetición o cerradura, la cual habitualmente se indica con el metacaracter ‘*’ y que asociado a una expresión regular, permite que esta se repita cero o mas veces.
Por ejemplo la expresión ‘a*’ que es la que habitualmente se pone como ejemplo, daría como resultado un lenguaje formado por las cadenas de cero o mas caracteres ‘a’: {ε, ‘a’, ‘aa’, ‘aaa’, …}. Formalmente podrían existir y serían distintos la representación del conjunto vacío, de la representación (ε) representada anteriormente.
Y ya para finalizar estas ideas básicas, que nos pueden ayudar a entender las expresiones regulares, el hecho de que se pudieran necesitar expresiones mas complejas, hizo necesario que se consideraran algunas operaciones más, o bien restringir las existentes, a partir de esas básicas. Si el metacaracter del (*) permitía que se pudieran definir cero o más repeticiones, se restringía a que existieran una o mas repetición, mediante otro metacaracter como el simbolo de la suma (+). El punto (.) ampliaba el conjunto de operaciones como comodín, concordando con cualquier caracter del alfabeto. Otra operación posible era considerar un intervalo de caracteres, de forma que no fuera necesario enumerarlos todos en una expresión usando el metacaracter de alternancia (|). Se propone habitalmente el guión (-) para ello. Como ejemplo, podeis imaginar la expresión A-Z equivalente a A|B|…|Z. Y nos queda, la operación de negación (no logico), que también habitualmente se representa mediante el metacaracter del circunflejo (^), aunque en otros caso podemos encontrar también la tilde (~) como equivalente.
Las expresiones regulares pueden ser agrupadas bajo identificadores que usados de forma recursiva permiten describir los lenguajes, formado parte íntima del proceso de analisis léxico de los compiladores, en el reconociento de tokens. Pero ese es un tema demasiado extenso y complejo para abordarlo desde la óptica de estas entradas, siendo mas propio de publicaciones técnicas entre las que personalmente os recomendaría el clásico «Compiladores, principios, técnicas y herramientas – Isbn 978-970-26-1133-2″ o bien «Construccion de Compiladores de Kenneth C.Louden – Isbn 970-686-299-4″ que han sido y son pasto de mi lectura y mi infinita curiosidad, en los ratos perdidos.
En wikipedia podeis encontrar una referencia al tema http://es.wikipedia.org/wiki/Expresi%C3%B3n_regular.
Necesariamente, al hilo de estos comentarios, al referirnos a las Expresiones Regulares en la entrada, solo las tendríamos en consideración en el contexto de las búsquedas, para localizar o reemplazar términos coincidentes con las expresiones, o bien como elemento que permite validar un texto respecto a una expresión, algo también muy habitual en nuestros programas.
Uso de expresiones regulares en el IDE: optimizar búsquedas en nuestro código.
Deciamos al principio de la entrada, que las expresiones regulares ya existían en el entorno de desarrollo. La búsqueda de términos en nuestro código va a ser algo importante y habitual de nuestro trabajo diario. Son muchas las ocasiones en las que abrimos la ventana de diálogo bien a través del menú de Delphi (Search -> Find / Search -> Find in Files), bien a través de las teclas de atajo rápido (Ctrl + F / Shift + Ctrl + F).
Respecto a versiones anteriores, no han existido cambios salvo los meramente cosmeticos. En Delphi 2007 y versiones anteriores, tanto la búsqueda sencilla como multiple tenían una ventana de diálogo común y mediante un selector, el usuario seleccionaba si quería buscar en la unidad actual o bien en las unidades del proyecto (o cualquiera de las alternativas). Las versiones siguientes, hicieron desaparecer dicha ventana de dialogo para la búsqueda sencilla, quedando embebida en el editor de código a modo de panel, con las distintas opciones que existían.

Y la ventana finalmente, quedaría reservada para la búsqueda en multiples ficheros.

Ahora podemos relacionar las operaciones que hemos visto anteriormente respecto a las expresiones, con la implementación concreta que hace el IDE. Como resultado, la ayuda en linea nos dice que existen disponibles para nosotros los siguientes metacaracteres:
| Descripcion | |
|---|---|
| ^ | Un circunflejo al principio de la expresión encuentra su coincidencia en el principio de linea. |
| $ | El signo del dolar finalizando la expresión hace coincidir con el final de linea. Para entender su uso podeis abrir un nuevo proyecto y escribir como término de busqueda la expresión «Form.$». En la imagen de ejemplo, veis que tan solo localizó una coincidencia, ya que le pedimos estrictamente que evalue coincidencias que se correspondan con el final de linea, precedidos de los caracteres «form» y un caracter cualquiera. Dicha condición solo la cumple el término resaltado. En la imagen os he marcado con una linea roja varios candidatos (3) de los cuales dos han sido excluidos. |
| . | Un punto representa a cualquier caracter. |
| * | Un asterisco tras un caracter o metacaracter en la expresión, permite encontar cualquier coincidencia en la que aparezca dicho caracter y cero o mas repeticiones del mismo. Una representación muy común para expresar cualquier caracter podría ser la combinación de los metacaracteres «.*». |
| + | Un signo de suma resulta similar al visto en el asterisco, salvo que excluye de las coincidencas cualquier cadena con cero repeticiones, es decir, igual al patron de búsqueda. |
| [ ] | El par de metacaracteres [] (corchetes) nos permitirán encontrar todas las coincidencias que combinen los caracteres incluidos en su interior.Creo que se verá mas claro con un ejemplo: En nuestro ejemplo, la petición era la expresión [orau] y como resultado encontramos 49 coincidencias, que combinan los caracteres incluidos en el corchete. |
| [^] | El metacaracter ^ tiene un significado especial al ser incluido en el interior de los corchetes, pasando a tomar el significado del no lógico, excluyendo de la coincidencia dichos caracteres. En el interior de una expresión puede ayudarnos a excluir resultados. La expresión «Form[^,]» en la imagen siguiente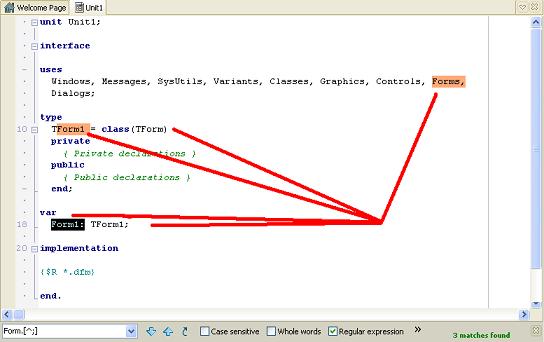 hace que solo existan 3 coincidencias, de todas las posibles (os las he marcado con una linea de color rojo). |
| [-] | El guión representa al rango de caracteres en el interior de un corchete. |
| { } | Las llaves permiten agrupar caracteres o expresiones, pudiendose anidar con un máximo de 10 grupos en una expresión sencilla. |
| Una barra invertida previa a cualquier metacaracter, permitiría desactivar el significado especial de éste, de forma que forme parte del alfabeto como cualquier otro caracter. Un ejemplo que me viene a la mente podría ser el uso de la barra invertida () al considerar una ruta de fichero como parte de la expresión. |
Aunque en la ayuda no aparece, también podemos usar el separador de alternativas «|» en nuestras busquedas. En la siguiente imagen se busca la expresion «Unit|Form» en la unidad del proyecto y son encontradas 7 coincidencias, entre las que aparecen tanto las coincidentes con Unit como con Form.

En el blog de Malcon Groves, podeis leer en inglés una introducción a este tema. Os aconsejo que le deis una lectura: Searching in Delphi Part 1 : Regular Expressions. La entrada se escribió en los primeros días del 2010, y formaba parte de un conjunto de reseñas de las novedades del IDE.
Yo también creo, como reflexiona Malcon en su entrada, que cobra vital importancia que nuestras búsquedas sean agiles y que encontremos facilmente en nuestro código los términos deseados y en eso, puede ser una herramienta de infinita utilidad saber usar las expresiones regulares. Quizás no tengamos costumbre de usarlas pero la lectura de esta entrada, intenta que reflexionemos sobre el beneficio que podemos encontrar en su uso cotidiano.
Hace unos días encontraba un pequeño problema durante la jornada laboral que dió origen a que me planteara escribir estas dos entradas, abordando las expresiones regulares. El proyecto era amplio, con una gran cantidad de unidades. Ademas existian varios proyectos vinculados a un grupo de proyecto. Y me planteaba la feliz idea de reemplazar un componente en todas las unidades que pudieran aparecer, con el objetivo final de sustituir su uso por otro componente similar ya existente en el proyecto, unificando así ambos en uno solo. Las busquedas en casos así son de vital importancia y hacerlas con agilidad, devolviendo resultados precisos permiten que realicemos la tarea de forma optima. El agrupamiento de resultados no ayudaba demasiado ya que no se ordena alfabeticamente sino que los resultados son agrupados en el mismo orden en el que aparecen las unidades en el proyecto. En mi opinión aquello era un gran error, ya que algunas de las decisiones respecto a los resultados se favorecen si se cuentan con distintos métodos de ordenación y resulta un caos tomarlas sin esa ordenación precisa. De ahí que me viese obligado a estudiar si las expresiones podían ayudarme, cumpliendo ese comentario que tantas veces hemos compartido y que viene a decir que el blog se alimenta de las necesidades que hemos tenido en el desrrollo de nuestro trabajo. 😉
En la siguiente parte, vamos a abordar la integración en la RTL de las Expresiones Regulares, que ha sido una de las novedades en XE (ahora ya estamos en condición de estudiarla). Así que os emplazo a que en un breve periodo de tiempo nos volvamos a encontrar en la segunda parte de esté artículo.
Espero que os haya sido de utilidad y os animo a que participeis de forma activa en la Comunidad.
Un abrazo a todos.

Tema interesante, desconocido y extenso.
Supongo que como no es algo que se utiliza habitualmente, no estamos (al menos yo) familiarizados con su utilización. Supongo que es de aquellas cosas de las que no te acuerdas hasta que no lo necesitas y entonces te das cuenta de la importancia que tiene el poder contar con ello (con unas librerías que te faciliten el trabajo -en este caso-).
Muy interesante la entrada Salvador. Queda «apuntado» para seguir en hilo con las siguientes partes.
Un saludo.
Me gustaMe gusta
Hola Germán:
Yo tampoco estaba familiarizado con el tema, pero reconozco me ha servido de gran ayuda y quizás por eso el comentarlo.
Yo creo que sería interesante que añadieran que el agrupamiento de resultados cuando se busca en el IDE, en el dialogo de varios archivos, permitiera visualizar los resultados en la ventana de mensajes por orden de la ruta (alfabetico) y no solo por el orden de las unidades en el proyecto. Y además no creo que fuera nada dificil ni complicado. Creo que ayudaría en algunos casos.
Y si me apuras, incluso te diría sería interesante poder ampliar la busqueda al dfm, ya que en ocasiones hay terminos que buscamos que no están recogidos en la implementación sino que se ha guardado en el formulario mediante persistencia, caso habitual cuando almacenamos las sentencias sql en los querys y tiempo despues necesitamos saber todas los modulos que acceden a una tabla cualquiera. 😦
Gracias como siempre por el comentario.
😉
Me gustaMe gusta